
Introduction: The Shift from Cloud to Client
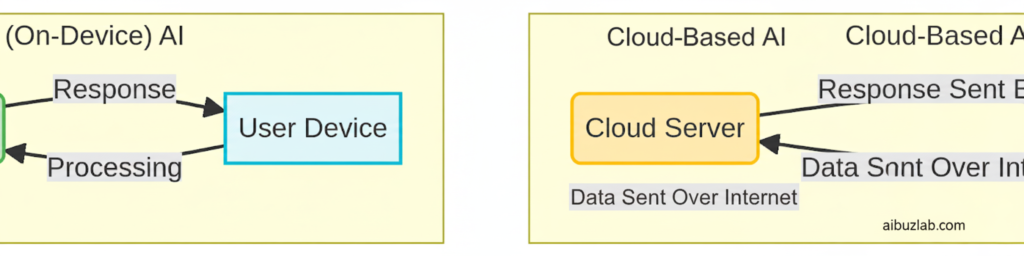
For years, the power of Artificial Intelligence (AI) was synonymous with the cloud. Large Language Models (LLMs) like GPT-4 and Gemini Pro required massive, centralized data centers to function, meaning every prompt, every piece of sensitive data, had to be sent across the internet to a third-party server.
However, a quiet revolution is underway: the rise of Local LLMs (Large Language Models) and On-Device AI. These are smaller, highly optimized models that can run directly on a user’s personal device—a laptop, a smartphone, or a desktop PC—without needing an internet connection or sending data to the cloud. This shift is not just a technical curiosity; it is a fundamental change that positions on-device AI as the future of privacy, security, and control for both consumers and businesses.
1. The Core Problem with Cloud-Based AI
The convenience of cloud-based LLMs comes with significant privacy and security trade-offs, particularly for sensitive business or personal data:
- Data Exposure: Every interaction is transmitted and stored on a third-party server, creating a potential point of failure and exposure. For highly regulated industries (finance, healthcare), this is often a compliance nightmare.
- Latency and Downtime: Performance is dependent on internet speed and the provider’s server load, leading to slower response times and service interruptions.
- Vendor Control: The user has no control over how their data is used for future model training or what policies the provider might implement.
2. The Unmatched Advantages of Local LLMs
Local LLMs solve these problems by moving the processing power directly to the user. The benefits extend far beyond simple convenience:
A. Absolute Privacy and Security
The most compelling advantage is data sovereignty. When an LLM runs locally, the data never leaves the user’s device.
- Zero Transmission Risk: Prompts, documents, and generated responses are processed entirely offline. This eliminates the risk of data interception during transmission and ensures that sensitive information remains within a secure, controlled environment.
- Compliance: For businesses, this local processing capability is a game-changer for adhering to strict data regulations like GDPR and HIPAA, where data residency and control are paramount.
B. Superior Performance and Control
By eliminating the need for network communication, local LLMs offer performance benefits that cloud models cannot match:
- Lower Latency: Responses are near-instantaneous because the model is running directly on the client’s hardware. This is crucial for real-time applications and complex, multi-step tasks.
- Offline Capability: The model functions perfectly without any internet connection, making it ideal for fieldwork, travel, or environments with poor connectivity.
- Customization and Fine-Tuning: Users have the freedom to load and fine-tune models with their own proprietary data (e.g., internal company documents) without sharing that data with any external entity.
3. Key Players in the Local LLM Ecosystem
The rapid development of smaller, highly efficient models has made local deployment a reality. These models are often referred to as Small Language Models (SLMs) and are optimized to run on consumer-grade hardware.
| Model Family | Developer | Size Range (Parameters) | Key Advantage for Local Use |
|---|---|---|---|
| LLaMA (e.g., Llama 3) | Meta | 8B to 70B | Open-source, massive community support, excellent all-around performance. |
| Gemma (e.g., Gemma 2) | 2B to 27B | Highly optimized for on-device performance, strong integration potential with Android/ChromeOS. | |
| Phi (e.g., Phi-3.5, Phi-4) | Microsoft | 3.8B to 14B | Exceptional reasoning capabilities despite small size, often outperforming larger models on specific benchmarks. |
| Mistral | Mistral AI | 7B to 8x22B | Known for high performance and efficiency, making 7B models highly usable on consumer hardware. |
These models are often deployed using specialized frameworks like GGML or GGUF, which quantize the models (reduce the precision of the weights) to dramatically decrease their size and memory requirements, allowing them to run efficiently on CPUs and consumer GPUs.
4. The Hardware Challenge and the Future of On-Device AI
While the software has advanced rapidly, the main bottleneck remains consumer hardware. Running a powerful LLM locally still requires a device with sufficient RAM and a capable Neural Processing Unit (NPU) or GPU.
- Current Reality: Lightweight models (e.g., Mistral 7B, Llama 3 8B) can run effectively on modern laptops and even some high-end smartphones (like the latest iPhone or Samsung Galaxy models).
- Future Trend: Hardware manufacturers are rapidly responding. New CPUs and GPUs are being designed with dedicated NPUs specifically to accelerate AI tasks. This trend, often called the “AI PC” or “AI Phone,” will soon make it standard for devices to run powerful LLMs locally at high speed.
Conclusion: The Inevitable Privacy Pivot
The shift to Local LLMs is inevitable because it aligns with the fundamental user demand for privacy, security, and control. For businesses, it represents a path to leveraging powerful AI without compromising proprietary data or violating compliance mandates.
While cloud-based LLMs will continue to serve as powerful general-purpose tools, the future of specialized, sensitive, and real-time AI processing belongs to the local model. By understanding and adopting this technology, businesses can unlock the full potential of AI while keeping their most valuable asset—their data—securely in-house.